作者|杨青编辑|李忠良
作者|杨青编辑|李忠良
随着大数据与人工智能的引入,金融风控领域出现了很多探索与创新。就在QCon全球软件开发(北京站)2021,我们邀请到了度小满数据智能部总经理,技术委员会执行主席杨青分享了度小满在金融领域的实践,本文是杨青的分享整理文稿,希望对你有所启发~
今天我将分享三方面的内容:信贷风控流程、模型效果的四大挑战以及度小满风控创新式探索。

风控流程包含贷前、贷中以及贷后三部分。
从模型角度来看,风险端涉及贷前、贷中、贷后三大信用评分。除此以外还有很多辅助模型提升风险识别能力,反欺诈模型、预授信模型、预催收模型等等。
从经营侧角度来看,除了关注风险之外,金融公司还需要关注盈利性、用户的满意度等。
在贷前阶段,定价需要关注用户对利率的敏感性,定额需要关注用户的资产情况;在贷中阶段,流失率是需要着重关注的指标,这里会涉及流失模型、Offer满意度模型等等。
1风控模型四大挑战
复杂场景下的智能金融风控挑战有以下四类:数据孤岛、非结构化信息、复杂模型的可解释性以及内外部场景个性化建模。
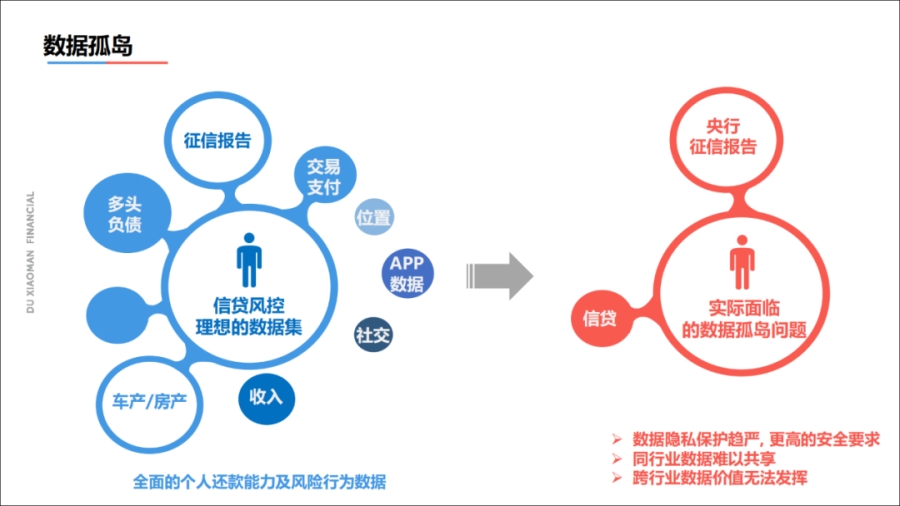
在数据孤岛方面,我们知道做大数据信贷风控,最理想的情况是能够拿到用户的准确用户画像,了解到用户的资产情况。
比如用户的月薪、是否有车、是否有房和股票基金、历史的借贷行为以及交易流水等等。
但是现实情况下获取全部数据比较难,绝大部分公司仅仅通过查询征信报告来进行授信,很多数据可能需要从外部获取,但是数据监管越来越严格,跨行业的数据交换越来越难。
数据隐私保护出现之后,联邦学习是一种很好的解决方式。数据无需出狱,仅仅交换模型的参数,就可以保证模型的效果。

征信报告还存在非常多的非结构化信息,这些信息为提升模型带来了非常大的挑战。
首先是一些家庭住址、公司地址等文本信息,如何去处理?
其次是图网络信息,在征信报告中,我们可以看到人与地理位置之间的关系、企业的人和人、公司和公司之间的关系,这些关联网络的信息怎么去挖掘?
再有是时序信息,它也是另一类非结构化信息,负债敞口的变化、整体额度授信场合的变化、用户还款行为的变化等等都是值得挖掘的信息;
另外在信贷经营过程中,公司会有很多与用户交互的信息,比如电销、信审以及催收的时候,存在非常多的语音交互信息,它里面存在非常多有价值的信息,如何挖掘和利用也是很大的挑战。
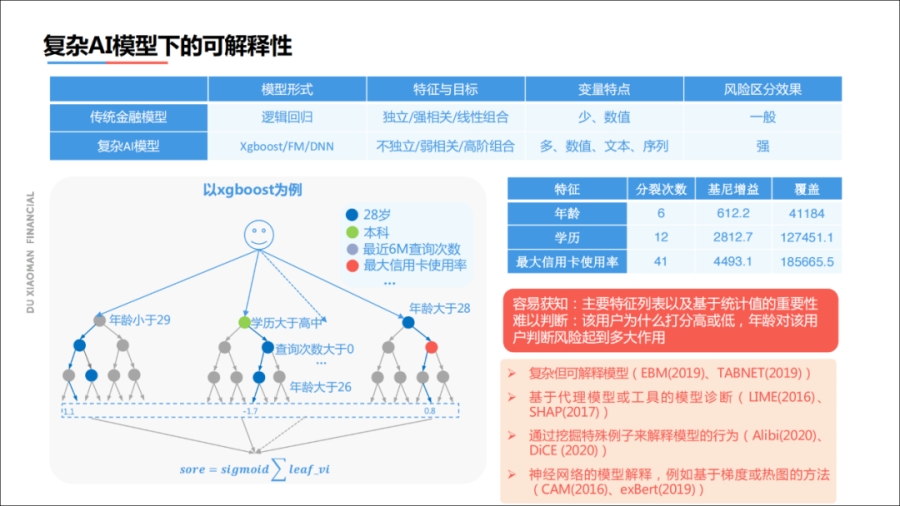
在复杂模型的可解释性方面,我们之前使用的客户特征大概只有十几维,单个特征与模型结果是强相关关系。我们很容易获得用户信用分较低的具体原因。
但是现在模型的参数非常多,特征数量也非常多,单个特征对于最终结果的影响非常微弱,解释性比较差。
我们以xgboost为例,一个模型可能存在几百个数组,当我们建模时,每次都是优化已有结果与目标结果值来决定,这种残差的优化方式,使xgboost模型效果具有很好的区分度。
但是当我们建了第一棵树之后,再接着建第二棵树的时候,还会使用已有的特征来选择新分类节点。
因此一个特征出现在决策树模型的多棵树中,我们就很难解释最终的结果。
大家可能计算xgboost模型特征重要度,但是这仅仅得到模型本身的特征重要度排序,我们无法应用具体到一个案例,无法解释单个个体是否降额、升额的原因。
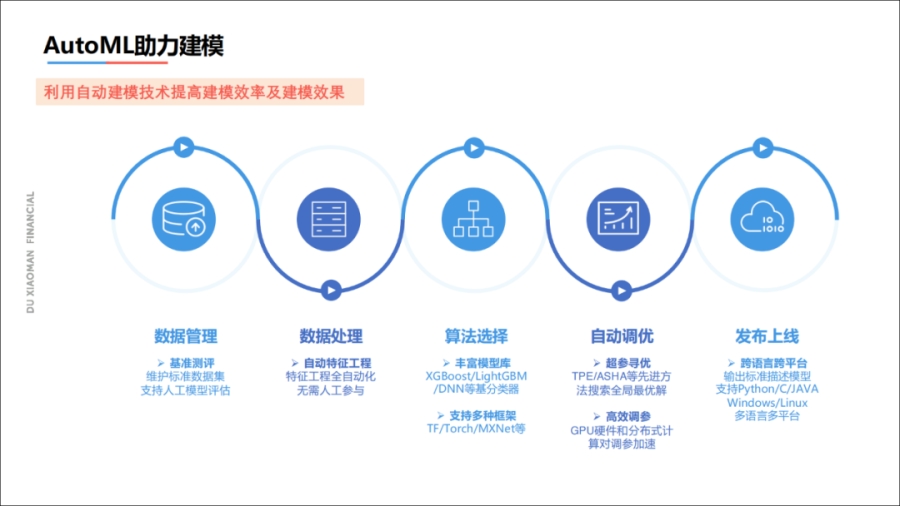
业务模型非常多,度小满有数千个模型,我们研发AutoML来助力建模,从特征管理、算法选择、模型的自动调优上线都使用AutoML,一些简单模型完全实现了自动化。
对于一些复杂的模型,通过AutoML也能达到往往比人工还好的效果。目前在度小满,所有模型上线之前必须要通过AutoML机制。
2如何处理非结构化信息?
上述的每一项挑战都是非常大的话题,这次分享我将会聚焦在如何处理非结构化信息挑战。
每家金融公司的数据源都不一样,但是唯独征信报告都一样。我把度小满征信报告的解读技术,拆分成了4个阶段。
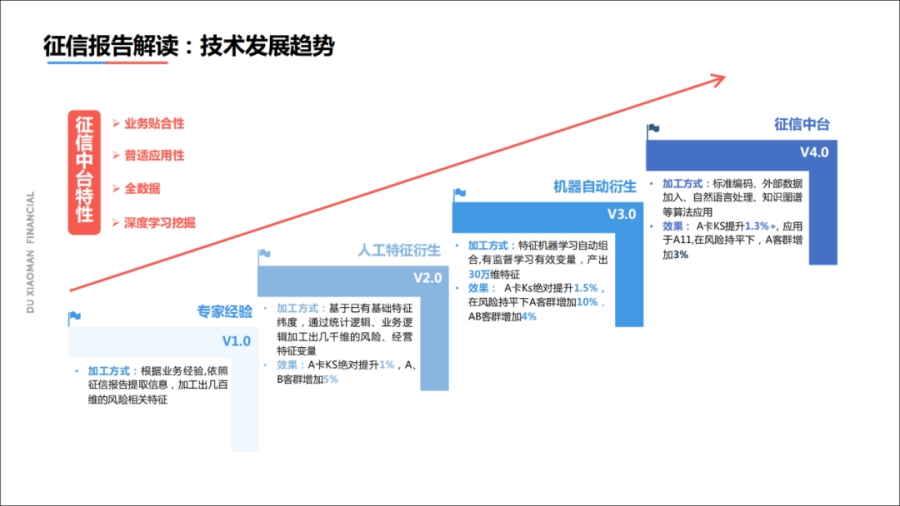
首先是专家经验阶段,这一阶段主要是依赖于工程师对金融业务的理解,人工地添加一些特征;
其次是人工特征衍生阶段,通过一些统计编号的方法,将特征进行衍生,特征数增加到了几千维;
接着是机器自动衍生阶段,可以达到30万维以上;
最后是中台阶段,我们将所有的NLP、知识图谱等算法集成起来,提供一体化的服务。
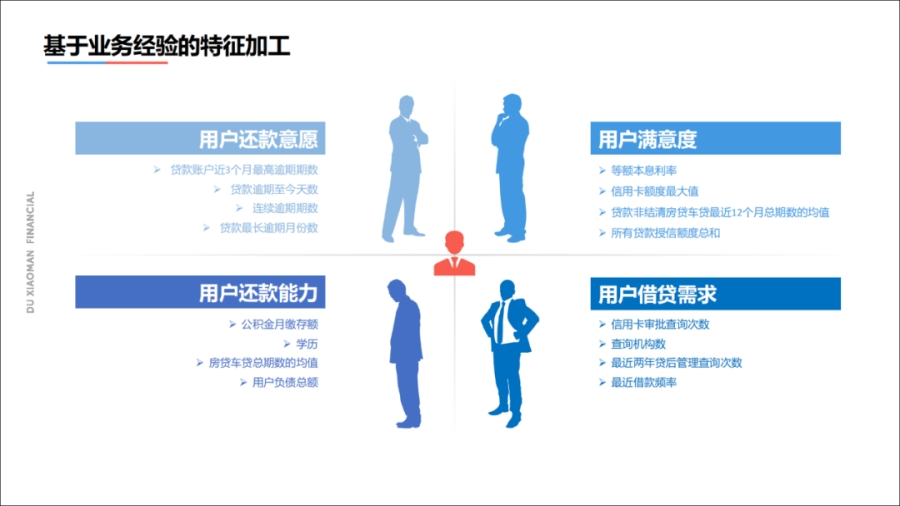
专家经验阶段和人工特征衍生阶段,其实主要依赖于人工经验。比如,当我做一个风控算法,风控算法的目标就是判断一个人是否会逾期?
我们会关注用户的还款意愿和还款能力,大家通过经验来增加一些变量,通过这些变量建模,来达到一个比较好的效果。
当我做征信模型的时候,可能更关心Offer满意度和用户借贷需求。在用户满意度方面,用户的借款账户在我司,是不是主账户?有多大的余额敞口等?
如果用户有30万的授信额度,其中18万是度小满的,那我们就相对比较满意。
在用户的借贷需求方面,用户流失是否因为产品不满意?还是因为没有需求而流失的?这里面会涉及信用卡的审批次数、借贷频次等变量。
这类基于人工经验的情况,对模型统计学要求比较高,需要我们对这个业务有洞察,工程师需要做大量的业务理解和特征工程工作,并且最终得出的特征系统完备性明显不足。
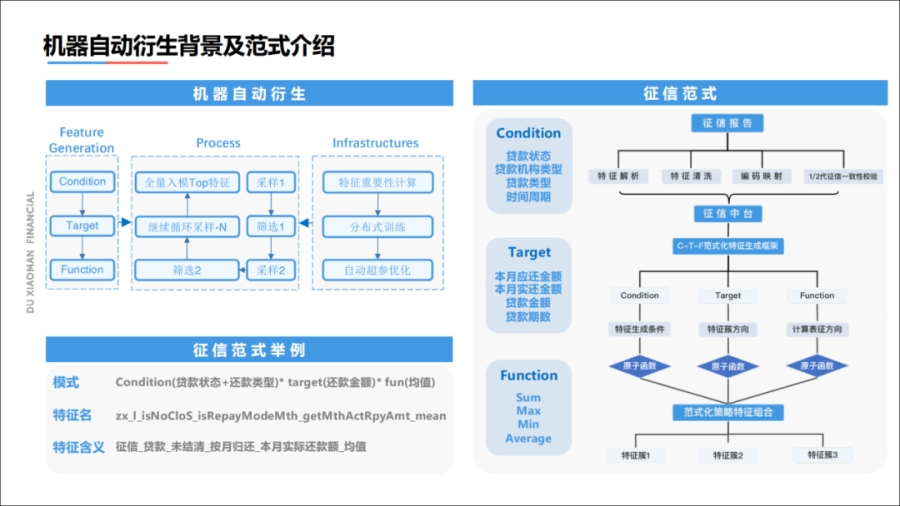
在征信机器自动衍生阶段,我们观察上图右侧的征信范式框架。征信报告里有非常多的细粒度原子操作,通过最大化地刻画这些细粒度,可以使原子操作之间进行各种交叉组合。
交叉组合之外,特征维度可能达到了几千万维,其中有大部分是稀疏和无效的。
我们会通过一些模型,通过分布式训练框架,训练一些有间隙度的模型出来,然后通过特征重要的排序。
我们最终挑选出了30万维的有价值变量,这些变量大概可以覆盖95%的业务需求,大大减少人工特征加工的工作量,提升了我们的效率,而且在模型效果上面也有明显的增加。
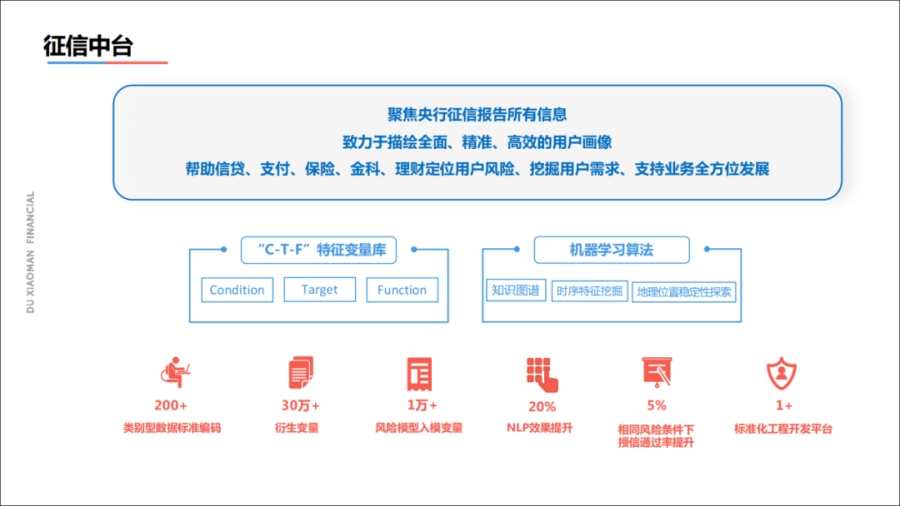
那么对于征信4.0阶段,我们发现征信报告还有非常多的有价值信息,我们通过NLP、图网络等模型,将征信的特征算法进行了打包,整个过程相当于一个中台服务。
我们内部有一个聚焦于征信报告全方位解读的小组,专门提供最准确的客户画像,为各种金融业务线赋能。
地理信息挖掘与自监督学习应用
首先是地理信息挖掘应用。用户的稳定性是非常重要的策略因素,如何从征信报告里架构好这个变量?
左上有一个表格,这是征信报告的一个原始信息,用户填写了三个信息,福州市闽侯区上甘镇五虎路、福州市闽侯区青口镇沪屿街、厦门市思明区民族路。
当我们对应到右边,进行特征统计的时候,数据无法对齐。
征信报告的信息都是用户自己填写,它存在各种省略的情况,也会存在错别字,所以首先我们需要进行PY数据归一化。
从省、市、区、县完全归一化之后,我们可以对居住地信息进行稳定性加工,比如用户的城市数、区域数、同一个区域居住时长。
对于征信报里面的公司名、行业以及工作地点也可以做同样的事,首先进行数据规一化,之后就可以进行特征的衍生与加工。
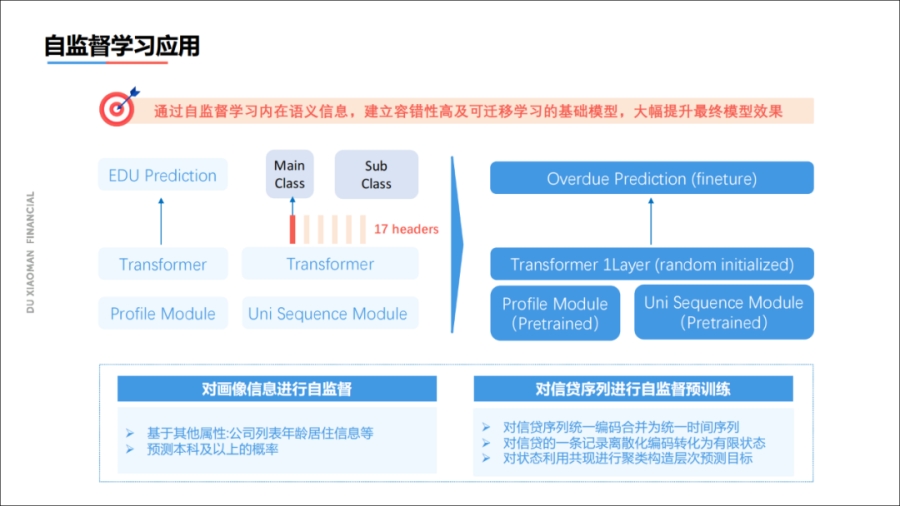
其次是自监督学习的应用,通过自监督学习征信报告的内在语言关系,建立高容错的、可迁移的模型,可以大幅度地提升业务效果。
所有的金融公司申请未通过、申请通过未用信的人占据大多数,但是这两种人也有征信报告,只是这样的报告是没有label的,我们无法知道用户是否会逾期。这种数据占了90%以上,当我们在建模的时候,大部分的无标数据都被浪费了。
度小满通过自监督学习的方式使用了这些数据,一方面,我们对用户画像(例如学历)进行Mask,通过征信报告的其他信息,自监督地预测学历情况;
另一方面我们对用户信贷的时序,进行统一的向量表达,减少一个特征维数,因为把之前没有使用到的信息使用起来了,业务获得了巨大的收益。
时序网路的探索
征信报里面有非常多的时序信息,例如贷款记录、中文信息、贷款机构、放款日期、本金输入类特征,针对不同的特征,需要进行不同的处理。
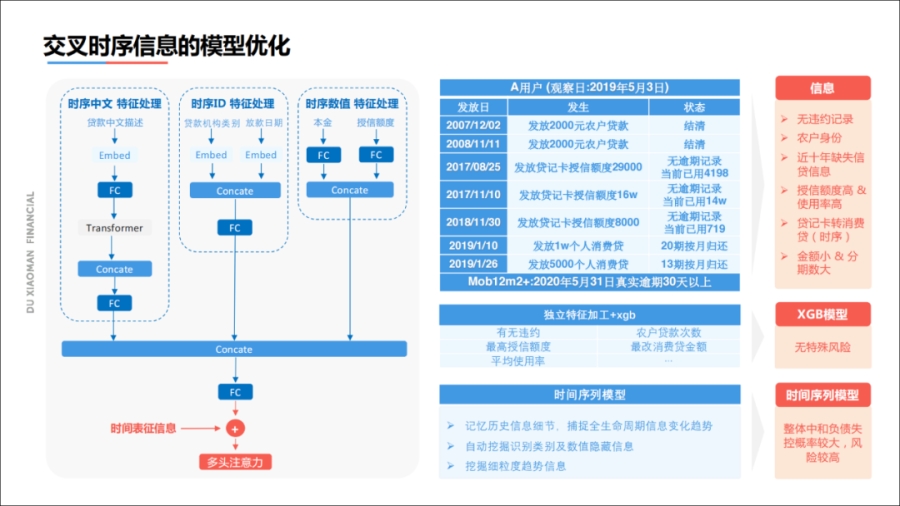
例如,对文本进行Transformer,累加上时序以及数类特征进行融合,把所有的一条序列按时间排序,加上Time的标签,最后进行多头注意力机制,通过时序网络了解到细粒度的时间变化趋势。
上图右方是一个时序模型发现以贷养贷的案例。
客户在2007、2008年分别有2000的农户贷款;2017年有的授信额度,在2017年后面有一笔16万的预授信,当前使用14万;在2018年又发放8000额度的贷记卡;到2019年申请了两笔个人消费贷,并进行了消费贷分期。
如果基于特征加工方式的话,从客户无违约、最高授信十六万元等情况,无法看出有什么异样。
在我们的普通模型中这位用户信用较为优良,但实际上此用户在2020年5月31日存在一次逾期。
再分析一下刚刚的案例,我们可以着重关注以下几方面的信息。
首先用户虽然无违约记录,但结合农户身份、10年来信息比较缺失、信贷资金使用率比较高等,我们感知到用户风险较大;
其次较为关键的是贷记卡金额转到消费贷,并且当消费贷转移完之后,用户还进行了较长期数的金融分期,这说明了用户的还款压力非常大。
上述案例告诉我们,通过这样的时序网络可以非常细致地观察到用户的时间变化趋势,能够更好地发现这种潜在的风险行为。
针对不同的时序行为,我们都做了同样的处理,并且在多种时序特征表达之上,我们进行了模块交叉,多头注意力机制,然后通过这种方法,我们希望能获得不同时序行为之间的关联关系。
通过时序行为变化,其实可以发现一些比较好玩的事情。
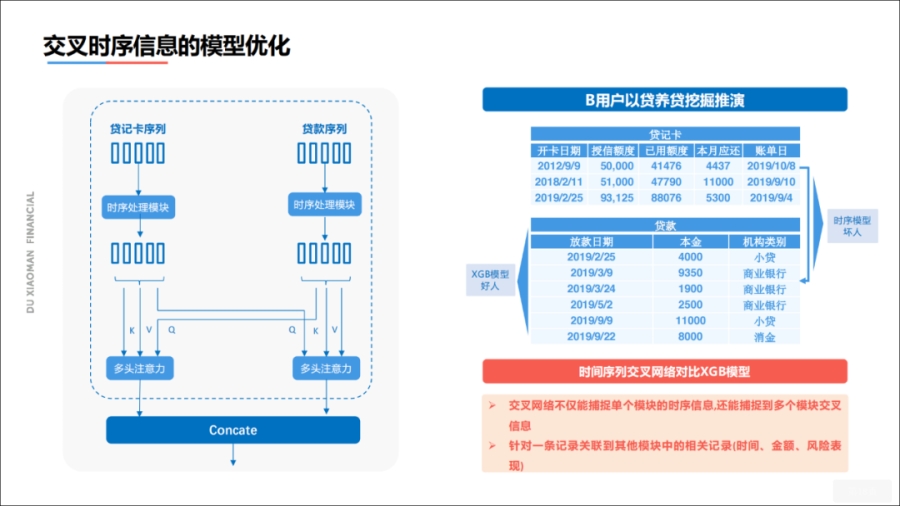
上述右图是一位历史无违约的用户,在2019年9月有三笔应还账单,大概分别是4437、、5300元,然后在同期此用户分别借了元的小贷和8000元的消费金融贷款,
我们可以观察到新借款的金额与待还款金额,在同一时间,额度非常接近,我们判定他是一位以贷养贷用户。
后来通过我们的电话调研,确实发现他存在以贷养贷行为。我们通过上述的时序关联关系,发现很多这样的潜在风险。
图模型发展与探索
接下来分享图模型发展在征信报告中的实践应用,征信报告中有非常强大的关键网络的关系,我们将它用在信用风险评估上。
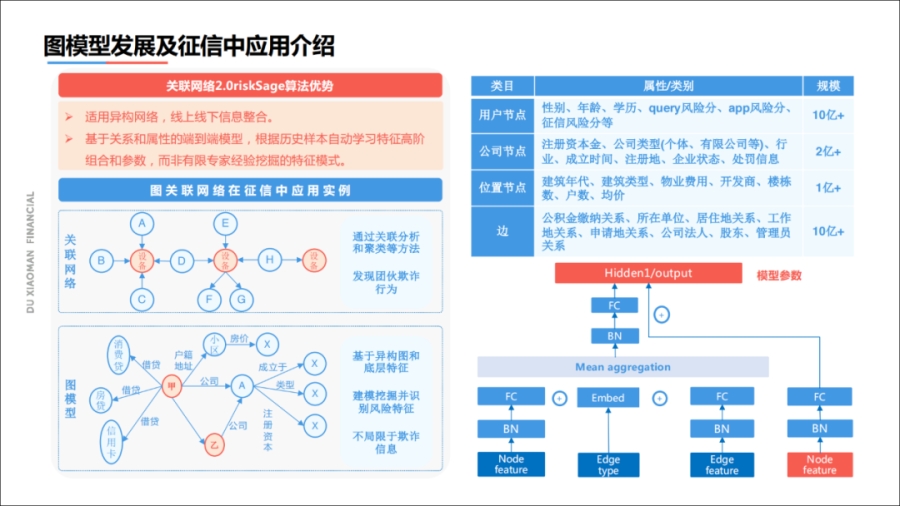
图模型是比较相对中等功能的异构图,有用户节点、公司节点、位置节点以及节点与边的关系,通过异构图的挖掘,我们能够发现很多问题。
比如说某一个用户可能是优良的人,但它所关联的公司里面有很多逾期的人,这里边存在很大的风险。
我们之前发现过一个案例,用户所在公司里面存在大量的违约人员,原因是这个公司进行吸储放贷,员工将自己的钱存储在公司,公司支付其较高的利息。
很多员工会为了赚钱,然后通过借贷赚息差的方式盈利,最后这家公司暴雷,逾期的用户非常多,通过这种关联关系挖掘就可以识别这种情况。
3未来展望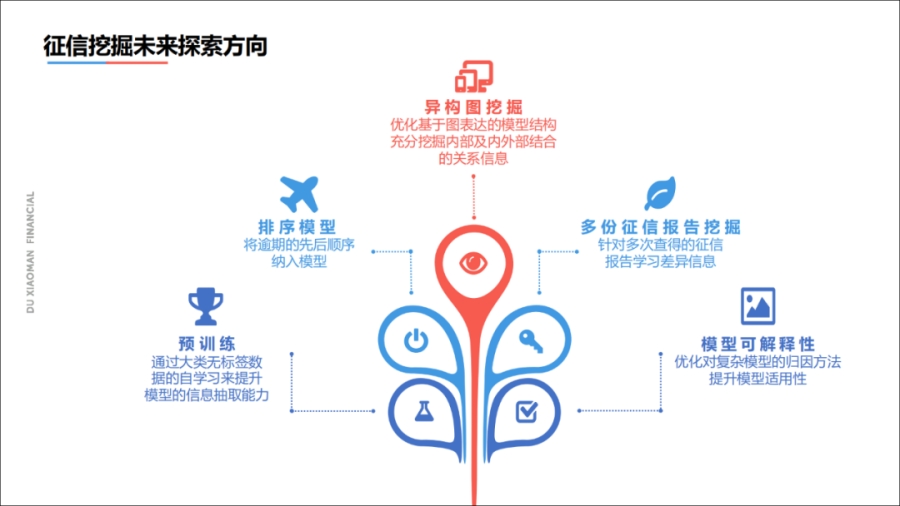
首先是预训练模型深度应用,征信报告里存在大规模无标签的数据,通过预训练模型学习提升模型的信息提取能力;
其次风险模型本质是一个排序模型,之后我们会将逾期的先后顺序纳入模型;
第三是异构图的挖掘,这里还有非常多的算法可以尝试;
第四是多份征信报告的挖掘,如果用户是老客户的话,生命周期比较长,会涉及很多份征信报告,我们需要针对多次查询的征信报告学习差异信息;
最后是模型的可解释性,我们需要优化对复杂模型的归因方法,提升模型的实用性。
以上就是我今天的分享,谢谢大家。
4活动推荐
11月5-6日,AICon全球机器学习与人工智能大会(北京站)2021设置了【NLP技术与应用】专题,度小满技术委员会执行主席杨青担任专题出品人,我们一起邀请了业界四位NLP专家,为你分享NLP在各大厂的实践。

除去NLP专题外,还有人工智能前沿技术、通用机器学习技术、计算机视觉实践、智能金融技术与业务结合、推荐广告技术与实践、AI工程师团队建设与管理、认知智能的前沿探索、AI与产业互联网结合、大数据计算和分析、大规模机器学习算法及应用、智能语音前沿技术应用、大规模预训练模型进展、自动驾驶技术等,共14个专题。
更多精彩议题敬请期待!
目前大会门票限时特惠中,购票欢迎联系票务小姐姐文柳:(电话同),点击底部【阅读原文】可以了解更多大会信息。